もぐもぐ~おかゆ~!🍙
はじめまして。カバー株式会社コマース本部プラットフォーム部でエンジニアをしているKです。
この記事は、認証統合基盤・ホロライブアカウントの仕様書の「鮮度」を保つため、コーディング支援AIを活用して、保守を仕組み化した取り組みをご紹介します。
はじめに
ホロライブアカウントは、ホロライブプロダクションの各サービスを横断する認証統合基盤です。1つのアカウントで複数サービスにシングルサインオンできる仕組みで、複数のコンポーネントに分かれて開発しています。仕様書は実装とは別リポジトリで管理しています。
ところが、この仕様書の鮮度を保つのが大変です。
書いた瞬間は正確なのですが、実装が進むにつれて少しずつ現実と離れていく。
開発中には「この仕様だとエッジケースで破綻する」「レビューでより良い設計が見つかった」といった理由で、コード側が仕様書から先に進んでいく場面が日常的に起こります。そのたびに仕様書も更新すればいいのですが、目の前の実装を優先するうちに、つい後回しになる。
「仕様書のエラーコードが実装と違う」「バリデーションルールが変わっているのに仕様書はそのまま」、こういうズレが静かに溜まっていきます。どこのチームでも覚えのある話ではないでしょうか。
仕様書が古いと、テストの前提条件にズレが生じて不要な確認コストが発生したり、新メンバーのオンボーディングで「ドキュメントと動きが違うんですが」と毎回確認が走ったりします。また、認証認可基盤の特徴として、そもそも異なる開発チームと接続する開発が多いため、APIの開発が出来ていても、テストの段階で仕様を確認する時に「コードしかない」状態だとコミュニケーションがままならないこともあります。限られたリソースの中で、仕様書と実装の整合性を人手で維持し続けるのは現実的に厳しいものがありました。
そこで、コーディング支援AIがソースコードを直接読み、仕様書との差分を検出・修正し続ける仕組みを作ることにしました。
どんな構成にしたか
仕様書専用のリポジトリを用意して、Claude Code(AI) が動く環境を整えました。構成のイメージは以下のとおりです(実際の構成とは異なります)。
docs-repo(仕様書リポジトリ)
├── orientation/ # システム理解の基礎資料
├── specs/ # 機能仕様(複数ファイル)
├── reference/ # API一覧・影響範囲マップ
├── test-cases/ # テストケース(MD + CSV)
├── operations/ # 運用資料
└── .claude/
├── CLAUDE.md # AIへのコンテキスト定義
└── skills/ # ワークフロー手順(skill)
AIへの指示は CLAUDE.md と .claude/skills/ にMarkdownで記述し、スラッシュコマンドで呼び出す形にしました。
/sync-spec # 仕様と実装の差分チェック・更新
/check-consistency # 仕様書間の整合性チェック
/create-spec-issues # 不整合をGitHub Issueに登録
/create-test-cases # テストケースの自動生成一部内容をご紹介します。
/sync-spec は実行すると、本番デプロイ済みのバージョンを基準に、OpenAPI定義・バックエンドの実装・インフラ設定ファイルを実際に読み、仕様書と比較して差分を分類します。
仕様が古い → 実装に合わせて自動修正
TBD解消済み → TBD を削除して確定情報を記載
仕様に未記載 → 追記候補として提示
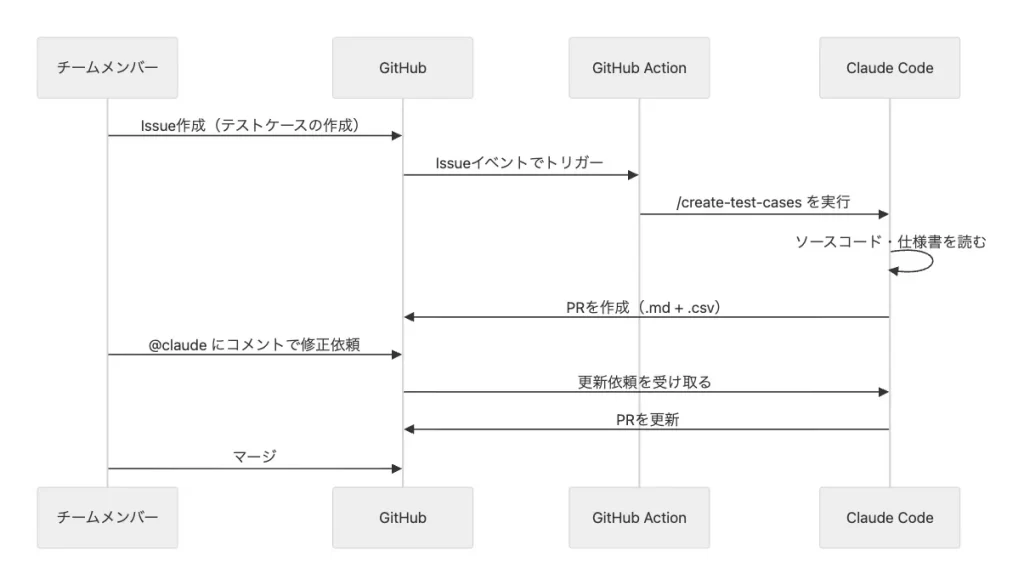
実装に未存在 → 確認してから削除テストケースの自動生成(/create-test-cases)はGitHub Actionsとも連携しており、Issueを作るだけで自動的にPRが生成されます。コマンドを知らなくても、Issueを立てるだけで使える形です。
やってみて分かったこと
AIは禁止しないと推測で書いてしまう
最初にハマったのがこれでした。仕様書を更新する際、AIがソースコードを確認せずに推測で書いてしまう。実装では 409 Conflict を返しているのに、文脈から 400 Bad Request と書く、といったことが起きました。
対策として、CLAUDE.md に原則を明記しました。
実装確認: 仕様書にAPI名・関数名・処理順序を書く際は必ずソースコードを読んでから書く(推測不可)
ここまで明確に指定すると守ってくれるようになり、PRのdiffに「xxx.go のL120で確認」のような根拠が残るようになりました。「やってほしくないこと」を暗黙の前提にせず明文化するのが大事だと感じています。
意図的な設計差異を「誤検知」させない
整合性チェックを回し始めると、意図的な設計判断まで「不整合」として報告されてきました。どのシステムにも、歴史的経緯で一見矛盾に見えるが合理的な理由がある、という設計判断があると思います。
対策として、設計判断を番号付きで記録するファイルを作りました。
## DD-01: 〇〇と△△の命名差異
〇〇フローと△△フローで異なる名前が使われている。
これは(経緯の説明)であり、意図的な差異。
修正の予定はない。ルールファイルに「ここに記録されたものは不整合として扱わないこと」と指定しておくことで、同じ指摘が繰り返されなくなりました。
仕様書の保守から実装の考慮もれが見つかる
仕様書の保守だけでなく、実装側の考慮もれを見つけられるようになったのも大きな変化でした。AIが仕様書とソースコードの両方を読んでいるので、「仕様書には書いてあるけど実装されていない」「この条件のときの挙動が実装に抜けている」といった差分が見つかるようになります。
こうした差分は /create-spec-issues でGitHub Issueとして起票し、実装側のリポジトリにフィードバックしています。仕様書を整備していたら、実装の改善点も見つかるようになった、という流れです。
導入してから何が変わったか
仕組みを回し始めてから、いくつか目に見える変化がありました。
仕様書が古いまま放置される期間が大幅に短くなった
/sync-spec を定期的に実行することで、以前は後回しになりがちだった仕様書の更新が実装と同じサイクルで回るようになりました。
テストケース設計の手戻りが減った
仕様書の記載が実装と一致した状態で維持されるようになったことで、仕様書を起点にテストケースを組んでも前提条件のズレが起きにくくなりました。
オンボーディングに変化があった
仕様書が信頼できる前提で読めるようになったことに加え、仕様書リポジトリ自体がClaude Codeの環境として構成されているため、新メンバーが不明点をClaude Codeに直接質問しながらキャッチアップできるようになっています。仕様の背景や設計判断の経緯もドキュメントとコンテキスト定義に集約されているので、人に聞かなくても正確な情報にたどり着きやすくなりました。
おわりに
大きな機能変更時の仕様書全体の整合性など、まだ人間の判断が必要な領域は残っています。今後は仕様書と実装の乖離を定期的に検知してチャットツールに通知するなど、より能動的に回る仕組みにしていきたいと考えています。
この取り組みを通じて一番感じたのは、AIが間違えにくい環境を設計することの重要性でした。推測禁止、実装確認必須、設計判断の明示化など、丁寧に言語化しないと制約なしに使った場合に精度が安定しません。そして、その制約を設計し、出力の正しさをレビューできるのは、実装を理解しているエンジニアだからこそです。AIの活用が進むほど、「AIが力を発揮できる環境を設計する」というエンジニアの役割が重要になっていくのだと感じています。
仕様書が正確であることの恩恵はすぐには見えにくいですが、テストの品質、新メンバーが立ち上がる速度、問い合わせ対応のスピードにじわじわ効いてきます。地味な取り組みですが、そういうインフラを整えることに面白さを感じています。